Since August 2018 the OpenCV CUDA API has been exposed to python. To get the most from this new functionality you need to have a basic understanding of CUDA (most importantly that it is data not task parallel) and its interaction with OpenCV. Below I have tried to introduce these topics with an example of how you could optimize a toy video processing pipeline. The actual functions called in the pipeline are not important, they are simply there to simulate a common processing pipeline consisting of work performed on both the host (CPU) and device (GPU).
This guide is taken from a Jupyter Notebook which can be cloned from here. The procedure is as follows, following some quick initialization, we start with a base implementation on both the CPU and GPU to get a baseline result. We then proceed to incrementally improve the implementation by using the information provided by the Nvidia Visual Profiler.
On a laptop RTX 2080 paired with an i7-8700 the final CUDA incarnation resulted in a speed up of ~30x and ~10x over the naive CPU and GPU implementations.
Initialization
Expand for initialization parameters
import osimport timeimport numpy as npfrom functools import partialimport matplotlib.pyplot as pltimport cv2 as cvvidPath = os.environ['OPENCV_TEST_DATA_PATH'] +'/cv/video/768x576.avi'lr =0.05rows_big =1440cols_big =2560check_res =Falseframe_device = cv.cuda_GpuMat()
Base implementations
To start with we simply loop through all the frames in the source video passing them through the video processing pipeline without considering any optimization steps. Because the video is decoded using the CPU the main difference between the CPU and GPU versions is that the frames are uploaded and downloaded to the GPU on every iteration, for details you can expand the code blocks below.
Expand to inspect the source code
def ProcVid0(proc_frame_func,lr): cap = cv.VideoCapture(vidPath)if (cap.isOpened()==False): print("Error opening video stream or file")return n_frames =0 start = time.time()while(cap.isOpened()): ret, frame = cap.read()if ret ==True: n_frames +=1 proc_frame_func(frame,lr)else:break end = time.time() cap.release()return (end - start)*1000/n_frames, n_frames;
The output gpu_time_0 from above is the average amount of time to process each frame, recorded on the host. This will be referred to as the frame time and is the value that we want to reduce. In order to achieve this we need to investigate what is actually occurring on the host and device for each frame. Luckily the Nvidia provides a useful visual tool for this, the Nvidia Visual Profiler.
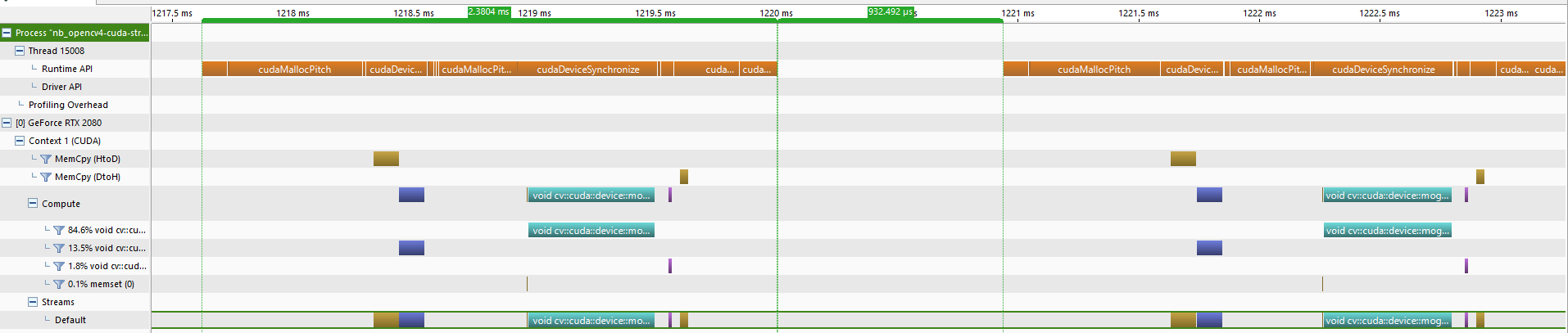
The image above shows the Nvidia Visual Profiler output from processing 2 of the 100 frames. Important things to be aware of here are:
The runtime API calls in brown which in this example represent the time the host (CPU) spends waiting for the device (GPU) calls to return.
The remaining blocks which show the time spent on the device. This is split according to the operation (kernel, memset, MemCpy(HtoD), MemCpy(DtoH)) as well as by the CUDA stream which the operations are issued to. In this case everything is issued to the Default stream.
The 0.93ms gap in between the blocks of runtime API calls represents the time spent executing code on the host, here that is the time taken for OpenCV to read and decode each video frame, frame = cap.read().
In this naive implementation all device calls from the host are synchronous and as a result the difference between (1) and (2) can be interpreted as periods where no useful work is being performed on either the host or the device. The host is blocking waiting for the device to return and the device is also idle, allocating or freeing memory.
From now on for convenience, for a single frame, I will refer to 1), 2) and 3) as the runtime API time, device time, host time respectively. As shown the profiler output, the current runtime API time and host time are ~2.38ms and ~0.93ms.
Taking (1) and (4) into account from left to right the output from the profiler can be mapped to the python calls as:
(1217.62ms-1220ms) proc_frame_func(frame,lr): calls to the device to process the first frame (~2.38ms)
(1220ms-1220.93ms) frame = cap.read(): read and decode the second video frame on the host (~0.93ms)
(1220.93ms-) proc_frame_func(frame,lt): calls to the device to process the second frame
Clearly from the gaps described in (4) a lot of time is wasted waiting for the device calls to return, and as the host time does not overlap the device time, there is a lot of room for improvement.
Hypothesis
The main causes of (4) are the blocking calls to both
cudaMallocPitch() - OpenCV in python automatically allocates any arrays (NumPy or GpuMat) which are returned from a function call. That is on every iteration
ret, frame = cap.read()
causes memory for the NumPy array frame to be allocated and destroyed on the host and
causes memory for frame_device_big, fg_device_big and fg_device to be allocated and destroyed on the device.
cudaDeviceSynchronise() - if you don’t explicitly pass in a CUDA stream to an OpenCV CUDA function, the default stream will be used and cudaDeviceSynchronize() will be called before the function exits, stalling the GPU every time.
Next
Address the unnecessary calls to cudaMallocPitch(), by pre-allocating any output arrays and passing them as input arguments.
Pre-allocation of return arrays
The previous implementation is updated to pre-allocate and pass all the return arrays to the Python functions to avoid unecessary memory allocations. e.g. instead of
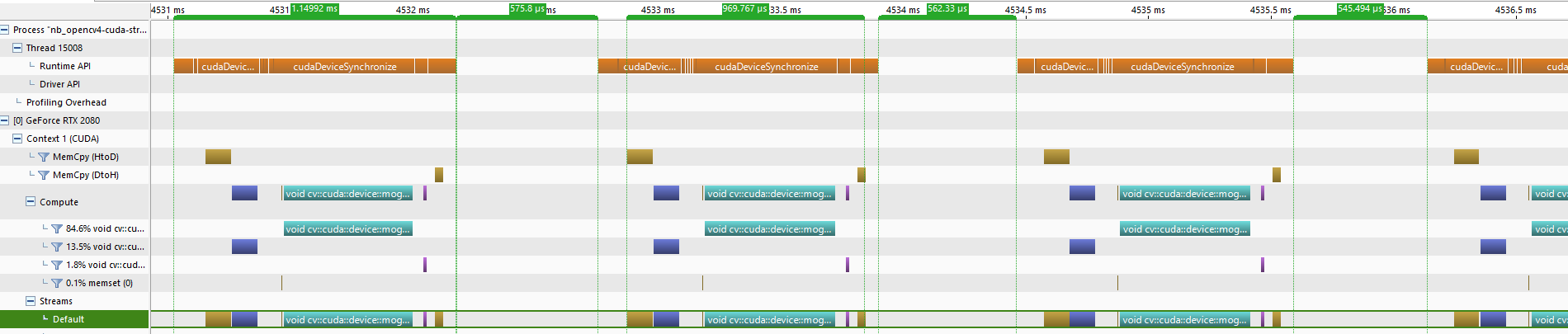
Pre-allocating the arrays has successfully removed the calls to cudaMallocPitch() and significantly (3 frames are now processed instead of 1.5) reduced (4), the time the host spends waiting for the CUDA runtime to return control to it.
Pre-allocation on the host has also reduced the host time from ~0.93ms to ~0.57ms. The host time will now be unaffected by the remaining changes we make and can be observed to be approximately constant after each of the following optimizations.
We will now proceed to try and reduce the runtime API time which in this step has already been fallen from ~2.38ms to ~1.15ms.
Hypothesis
As mentioned above by not specifying a CUDA stream all calls are placed in the “Default” stream which can be seen at the bottom of the figure. This means that due to the way OpenCV is implemented following each asynchronous kernel launch there will be an internal synchronizing call to cudaDeviceSynchronize() shown below:
Pass a non default CUDA stream to each OpenCV CUDA function.
Replacing the default stream
Each CUDA function is now passed the same non default CUDA stream to work in. This will prevent the calls to cudaDeviceSynchronize() after every function call. Because we have removed the synchronization calls an explicit call to self.stream.waitForCompletion() has to be made after we download the frame back from the device to the host to ensure the copy to self.fg_host has completed.
GPU 2 (replacing the default stream): 100 frames, 1.90 ms/frame
Incremental speedup: 1.05
Speedup over GPU baseline: 2.07
Speedup over CPU: 14.64
Analysis
Replacing the default stream
Observations
The calls to cudaDeviceSyncronize() have now been removed, and as a result the gaps between the device calls have disappeared, further reducing the runtime API time from ~1.15ms to ~1.07ms. That said it looks like the calls to cudaDeviceSyncronize() have just been replaced by calls to cudaMemcpy2DAsync().
Hypothesis
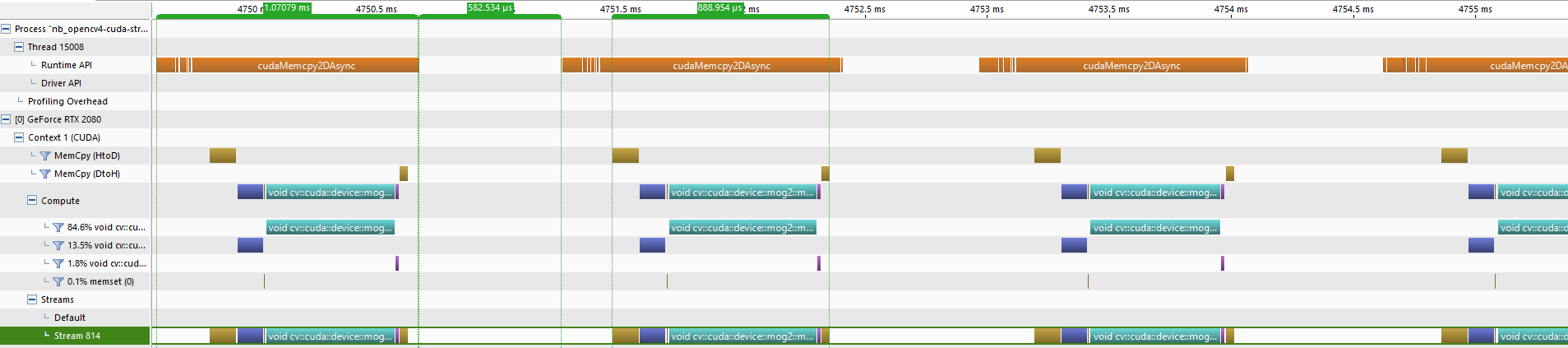
What has actually happened is we have tried to use asynchronous copies to and from the device without first pinning the host memory. Therefore what is shown are three asynchronous kernel launches and a synchronous copy from the device to the host, which blocks the host thread until all the previous work on the device is complete:
To force the copies to and from the device to be performed asynchronously with respect to the host the memory for both self.frame and self.fg_host is pinned.
GPU 3 (overlap host and device - attempt 1): 100 frames, 1.83 ms/frame
Incremental speedup: 1.04
Speedup over GPU baseline: 2.14
Speedup over CPU: 15.15
Analysis
Overlap host and device computation (1)
Observations
The output is now more intuitive, that said all that we have done is replace the calls to cudaDeviceSyncronize() with calls to cudaStreamSyncronize().
Hypothesis
We are issuing asynchronous calls to the device and then immediately waiting on the host for them to complete.
cv.cuda.resize(frame_device,(cols_big,rows_big),frame_device_big,stream=stream) async kernel 1bgmog2.apply(frame_device_big,lr,stream,fg_device_big) async kernel 2cv.cuda.resize(fg_device_big,fg_device.size(),fg_device,stream=stream) acync kernel 3fg_device.download(stream,fg_host.array) async copy DtoHstream.waitForCompletion() block until kernel 1-3and copy have finished
What we really want to do is overlap host and device computation by issuing asynchronous calls to the device and then performing processing on the host, before waiting for the asynchronous device calls to return. For two frames this would be:
Move the position of the synchronization point to after a new frame has been read as described above. To do this we also need to increase the number of host frame containers to two because moving the sync point means frame 0 may still be in the process of being uploaded to the device when we read frame 1. That is, when we call
ret,_ = cap.read(frame[1].array)
we have not synced, and we have no way to know if the previous call to
frame_device.upload(frame[0].array,stream)
has finished, hence we need to read to frame[1].array and not frame[0].array.
Overlap host and device computation (2)
We now run one frame behind, that is we start by reading frame 0 and asynchronously launching kernels to process it on the device as before however this time instead of immediately synchronizing with the host to retrieve the processed frame we continue reading frame 1 before calling self.stream.waitForCompletion().
This gives the device chance to process the kernels whilst we are decoding frame 1 on the host. The process then continues in this fashion until we reach the last frame where we have to synchronize immediately as there is no more host work to complete.
Expand to inspect the source code
def ProcVid2(proc_frame,lr,simulate=False): cap = cv.VideoCapture(vidPath)if (cap.isOpened()==False): print("Error opening video stream or file")return n_frames =0 start = time.time() while(cap.isOpened()): ret,_ = cap.read(proc_frame.Frame())if ret ==True: n_frames +=1ifnot simulate: proc_frame.ProcessFrame(lr)else:break proc_frame.Sync() end = time.time() cap.release()return (end - start)*1000/n_frames, n_frames;class ProcFrameCuda4:def__init__(self,rows_small,cols_small,rows_big,cols_big,store_res=False):self.rows_small, self.cols_small, self.rows_big, self.cols_big = rows_small,cols_small,rows_big,cols_bigself.store_res = store_resself.res = []self.bgmog2 = cv.cuda.createBackgroundSubtractorMOG2()self.stream = cv.cuda_Stream()self.frame_num =0self.i_writable_mem =0self.frames_in = [PinnedMem((rows_small,cols_small,3)),PinnedMem((rows_small,cols_small,3))]self.frame_device = cv.cuda_GpuMat(rows_small,cols_small,cv.CV_8UC3)self.frame_device_big = cv.cuda_GpuMat(rows_big,cols_big,cv.CV_8UC3)self.fg_device_big = cv.cuda_GpuMat(rows_big,cols_big,cv.CV_8UC1)self.fg_device = cv.cuda_GpuMat(rows_small,cols_small,cv.CV_8UC1)self.fg_host = PinnedMem((rows_small,cols_small))def ProcessFrame(self,lr):self.frame_num +=1if(self.frame_num >1):self.stream.waitForCompletion() # wait after we have read the next frameif(self.store_res):self.res.append(np.copy(self.fg_host.array))self.frame_device.upload(self.frames_in[self.i_writable_mem].array, self.stream) cv.cuda.resize(self.frame_device, (cols_big,rows_big), self.frame_device_big, stream=self.stream)self.bgmog2.apply(self.frame_device_big, lr, self.stream, self.fg_device_big ) cv.cuda.resize(self.fg_device_big, self.fg_device.size(), self.fg_device, stream=self.stream)self.fg_device.download(self.stream,self.fg_host.array)def Frame(self):self.i_writable_mem = (self.i_writable_mem +1) %len(self.frames_in)returnself.frames_in[self.i_writable_mem].arraydef Sync(self):self.stream.waitForCompletion()if(self.store_res):self.res.append(np.copy(self.fg_host.array))proc_frame_cuda4 = ProcFrameCuda4(rows_small,cols_small,rows_big,cols_big,check_res)gpu_time_4, n_frames = ProcVid2(proc_frame_cuda4,lr)print(f'GPU 4 (overlap host and device - attempt 2): {n_frames} frames, {gpu_time_4:.2f} ms/frame')print(f'Incremental speedup: {gpu_time_3/gpu_time_4:.2f}')print(f'Speedup over GPU baseline: {gpu_time_0/gpu_time_4:.2f}')print(f'Speedup over CPU: {cpu_time_1/gpu_time_4:.2f}')
GPU 4 (overlap host and device - attempt 2): 100 frames, 1.83 ms/frame
Incremental speedup: 1.00
Speedup over GPU baseline: 2.14
Speedup over CPU: 15.18
Analysis
Overlap host and device computation (2)
Observations
At first glance changing the synchronization point does not appear to have done anything the cudaStreamSynchronize() (stream.waitForCompletion()) still starts at the point just before the frame is processed on the device. On closer inspection we can see that the runtime API time (~1.5ms) now begins much earlier than the device time (~0.8ms) and as we intended overlaps the host time. That said we are not seeing any host/device processing overlap, so whats going on?
Hypothesis
This is most likely to be because we are working on Windows where the GPU is a Windows Display Driver Model device. See below for more details.
This would cause all the device calls from the previous frame to be queued and then issued when we call stream.waitForCompletion() and could explain the profiler output.
Next
Test the hypothesis by forcing the CUDA driver to dispatch all queued calls by issuing a call to stream.queryIfComplete() as shown below.
frame_device.upload(frames_in[0].array, stream) async copy HtoD, frame 0cv.cuda.resize(frame_device,(n_cols_big,n_rows_big),frame_device_big,stream=stream) async kernel 1, frame 0bgmog2.apply(frame_device_big, lr, stream, fg_device_big ) async kernel 2, frame 0cv.cuda.resize(fg_device_big,fg_device.size(),fg_device,stream=stream) acync kernel 3, frame 0fg_device.download(stream,fg_host.array) async copy DtoH, frame 0stream.queryIfComplete() force WDDM to dispatch any queued device callsret,_ = cap.read(frame[1].array) host read frame 1stream.waitForCompletion() block until kernel 1-3and copy have finished for frame 0
Overlap host and device computation (3)
The only change here is to add
self.stream.queryIfComplete() # kick WDDM
after the call to asynchronous download the processed frame has been issued, which should force the WDDM to dispatch any queued device calls.
Expand to inspect the source code
class ProcFrameCuda5:def__init__(self,rows_small,cols_small,rows_big,cols_big,store_res=False):self.rows_small, self.cols_small, self.rows_big, self.cols_big = rows_small,cols_small,rows_big,cols_bigself.store_res = store_resself.res = []self.bgmog2 = cv.cuda.createBackgroundSubtractorMOG2()self.stream = cv.cuda_Stream()self.frame_num =0self.i_writable_mem =0self.frames_in = [PinnedMem((rows_small,cols_small,3)),PinnedMem((rows_small,cols_small,3))]self.frame_device = cv.cuda_GpuMat(rows_small,cols_small,cv.CV_8UC3)self.frame_device_big = cv.cuda_GpuMat(rows_big,cols_big,cv.CV_8UC3)self.fg_device_big = cv.cuda_GpuMat(rows_big,cols_big,cv.CV_8UC1)self.fg_device = cv.cuda_GpuMat(rows_small,cols_small,cv.CV_8UC1)self.fg_host = PinnedMem((rows_small,cols_small))def ProcessFrame(self,lr):self.frame_num +=1if(self.frame_num >1):self.stream.waitForCompletion() # wait after we have read the next frameif(self.store_res):self.res.append(np.copy(self.fg_host.array))self.frame_device.upload(self.frames_in[self.i_writable_mem].array, self.stream) cv.cuda.resize(self.frame_device, (cols_big,rows_big), self.frame_device_big, stream=self.stream)self.bgmog2.apply(self.frame_device_big, lr, self.stream, self.fg_device_big ) cv.cuda.resize(self.fg_device_big, self.fg_device.size(), self.fg_device, stream=self.stream)self.fg_device.download(self.stream,self.fg_host.array)self.stream.queryIfComplete() # kick WDDMdef Frame(self):self.i_writable_mem = (self.i_writable_mem +1) %len(self.frames_in)returnself.frames_in[self.i_writable_mem].arraydef Sync(self):self.stream.waitForCompletion()if(self.store_res):self.res.append(np.copy(self.fg_host.array))proc_frame_cuda5 = ProcFrameCuda5(rows_small,cols_small,rows_big,cols_big,check_res)gpu_time_5, n_frames = ProcVid2(proc_frame_cuda5,lr)print(f'GPU 5 (overlap host and device - attempt 3): {n_frames} frames, {gpu_time_5:.2f} ms/frame')print(f'Incremental speedup: {gpu_time_4/gpu_time_5:.2f}')print(f'Speedup over GPU baseline: {gpu_time_0/gpu_time_5:.2f}')print(f'Speedup over CPU: {cpu_time_1/gpu_time_5:.2f}')
GPU 5 (overlap host and device - attempt 3): 100 frames, 1.23 ms/frame
Incremental speedup: 1.49
Speedup over GPU baseline: 3.19
Speedup over CPU: 22.60
Analysis
Overlap host and device computation (3)
Observations
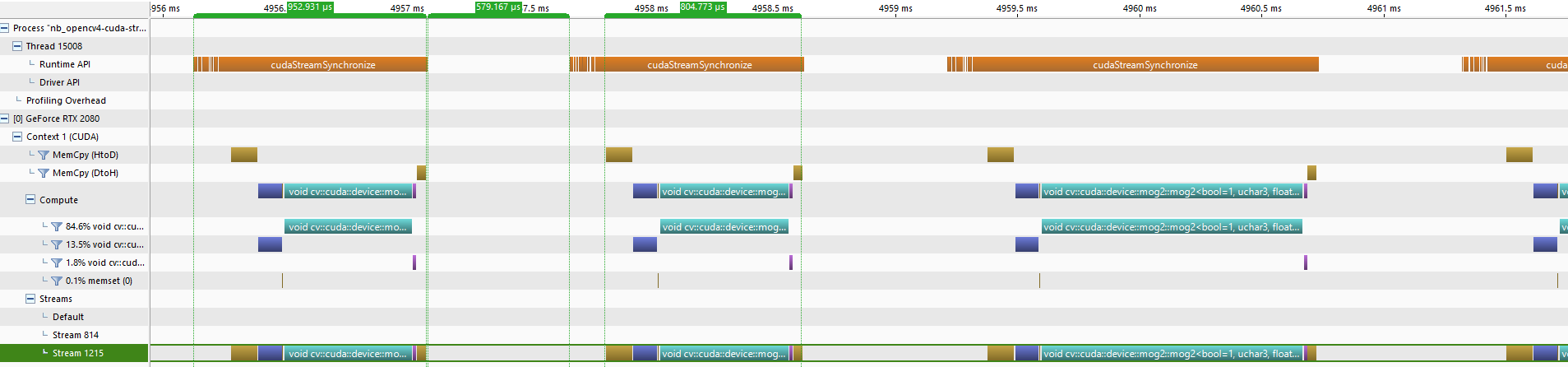
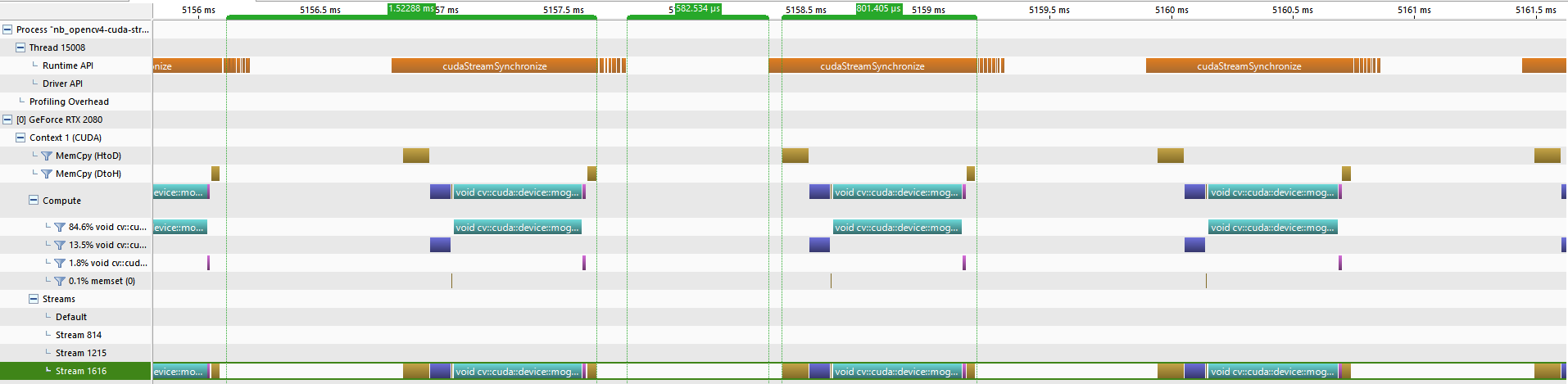
It appears as though the WDDM driver was at fault, by including the extra call to stream.queryIfComplete() we have finally overlapped the processing on the host and device. This can be observed in the profiler output where the host time (~0.62ms), overlaps the device time (~0.79ms) in Stream 2017. Notice also that there are gaps between the blocks of device time in Stream 2017 with the runtime API time (~1.07ms) still starting sometime before the device time and ending exactly after the Memcpy (DtoH) (fg_device.download(stream,fg_host.array)).
Most importantly the device is almost saturated with only the small gap (~0.2ms) in between each block representing the device time for each frame in Stream 2017. So what is causing this small gap?
Hypothesis
The device is stalling.
As already mentioned the host time cannot be changed. Additionally from the profiler output it is clear that the host time (~0.62ms) is less than the device time (~0.79ms).
That is given the processing pipeline below;
process frame 0 on the device ~0.79ms (copy frame 0 to the device execute kernel 1-3 and copy back to the host)
ret,_ = cap.read(frame[1].array)~0.62ms (read frame 1 on the host)
stream.waitForCompletion() block for (~0.17ms = 0.79ms-0.62ms) until processing for frame 0 has finished
stream.waitForCompletion() will on average cause the host to wait ~0.17ms for the device processing to finish. This can be observed in the profiler output by the length of cudaStreamchronize() which for each frame ends exactly following the Memcpy(DtoH). Unfortunately this wait stalls the device because it has no work to perform until more calls are issued by the host, which in this case does not occur until after the call to stream.waitForCompletion(). If only there was a way to issue work to the device in advance of stream.waitForCompletion(), which will continue to be performed afterwards.
Fortunately there is by using multiple streams, each processing a single frame at a time. This allows us to issue commands in advance, to process frame 1 before we start the wait on the host for frame 0, shown below
stream[1].waitForCompletion()block until (4) the processing for frame 1 has finished, allowing the device to continue with (7)
…
Notice that when stream[0].waitForCompletion() is called the device has Process frame 1 in stream 1 already queued up in stream 1 meaning that the wait on the host should not cause a stall on the device.
Note: Using multiple streams in this way will add additional latency and is not going to be suitable for real time processing, that said the additional latency in most real world cases will be tolerable and worth the reduction in processing time.
Next
Use multiple streams.
Overlap host and device computation - multiple streams
Expand to inspect the source code
class SyncType(): none =1 soft =2 hard =3class ProcFrameCuda6:def__init__(self,rows_small,cols_small,rows_big,cols_big,n_streams,store_res=False,sync=SyncType.soft,device_timer=False):self.rows_small, self.cols_small, self.rows_big, self.cols_big = rows_small,cols_small,rows_big,cols_bigself.n_streams = n_streamsself.store_res = store_res self.sync = syncself.bgmog2 = cv.cuda.createBackgroundSubtractorMOG2()self.frames_device = []self.frames_device_big = []self.fgs_device_big = []self.fgs_device = []self.fgs_small = [] self.streams = []self.frames = []self.InitMem()self.InitStreams()self.res = []self.i_stream =0self.n_frames =0self.i_writable_mem =0self.device_timer = device_timerifself.device_timer:self.events_start = []self.events_stop = []self.InitEvents()self.device_time =0def InitMem(self):for i inrange(0,self.n_streams +1):self.frames.append(PinnedMem((rows_small,cols_small,3)))for i inrange(0,self.n_streams):self.frames_device.append(cv.cuda_GpuMat(rows_small,cols_small,cv.CV_8UC3))self.frames_device_big.append(cv.cuda_GpuMat(rows_big,cols_big,cv.CV_8UC3))self.fgs_device_big.append(cv.cuda_GpuMat(rows_big,cols_big,cv.CV_8UC1))self.fgs_device.append(cv.cuda_GpuMat(rows_small,cols_small,cv.CV_8UC1))self.fgs_small.append(PinnedMem((rows_small,cols_small)))def InitStreams(self):for i inrange(0,self.n_streams): ifself.sync == SyncType.hard:self.streams.append(cv.cuda.Stream_Null())elifself.sync == SyncType.soft:self.streams.append(cv.cuda_Stream())def InitEvents(self):for i inrange(0,self.n_streams):self.events_start.append(cv.cuda_Event())self.events_stop.append(cv.cuda_Event()) def IncStream(self):self.i_stream = (self.i_stream+1)%self.n_streamsdef ProcessFrame(self,lr):self.n_frames +=1 i =self.i_streamself.IncStream() stream =self.streams[i]if(self.n_frames >self.n_streams andself.sync != SyncType.none): stream.waitForCompletion() # wait once both streams are used ifself.device_timer: self.device_time += cv.cuda_Event.elapsedTime(self.events_start[i],self.events_stop[i])if(self.store_res):self.res.append(np.copy(self.fgs_small[i].array))ifself.device_timer: self.events_start[i].record(stream)self.frames_device[i].upload(self.frames[self.i_writable_mem].array,stream) cv.cuda.resize(self.frames_device[i], (cols_big,rows_big), self.frames_device_big[i], stream=stream)self.bgmog2.apply(self.frames_device_big[i], lr, stream, self.fgs_device_big[i]) cv.cuda.resize(self.fgs_device_big[i], self.fgs_device[i].size(), self.fgs_device[i], stream=stream)self.fgs_device[i].download(stream, self.fgs_small[i].array)ifself.device_timer: self.events_stop[i].record(stream) stream.queryIfComplete() # kick WDDM def Frame(self):self.i_writable_mem = (self.i_writable_mem +1) %len(self.frames)returnself.frames[self.i_writable_mem].arraydef Sync(self):# sync on last framesif (self.sync == SyncType.none):returnfor i inrange(0,self.n_streams):if(notself.streams[self.i_stream].queryIfComplete()):self.streams[self.i_stream].waitForCompletion()if(self.store_res):self.res.append(np.copy(self.fgs_small[self.i_stream].array))self.IncStream() def FrameTimeMs(self):ifself.device_timer:returnself.device_time/self.n_frameselse:return0proc_frame_cuda6 = ProcFrameCuda6(rows_small,cols_small,rows_big,cols_big,2,check_res,SyncType.soft)gpu_time_6, n_frames = ProcVid2(proc_frame_cuda6,lr)print(f'GPU 6 (multiple streams): {n_frames} frames, {gpu_time_6:.2f} ms/frame')print(f'Incremental speedup: {gpu_time_5/gpu_time_6:.2f}')print(f'Speedup over GPU baseline: {gpu_time_0/gpu_time_6:.2f}')print(f'Speedup over CPU: {cpu_time_1/gpu_time_6:.2f}')
GPU 6 (multiple streams): 100 frames, 0.97 ms/frame
Incremental speedup: 1.27
Speedup over GPU baseline: 4.05
Speedup over CPU: 28.68
Analysis
Overlap host and device computation - multiple streams
Observations
The device is now completely saturated with memory operations overlapping kernel executions in Streams 2418 and 2419. Additionally the host and device time completely overlap each other. By saturating the device and overlapping host and device computation we have probably reached the limit of the optimizations we can apply to this particular toy problem.
Notice that as a result of the kernel/memory overlap the average device time is no longer equal to the average amount of time to process a frame on the device (streamed device time). In fact because of kernel/memory and host/device overlap the average device time should now be greater than both the average streamed device and frame time.
Hypothesis
If the above assumption is correct we should be able to see this effect by using device timers to get a more accurate value for the average device time.
Next
Use device timers to get the average device time. Unfortunately this introduces some overhead so we will have to compare this to the average time required to process each frame calculated without the device timers. This may mean that we may not see the difference that we expect.
Calculate the theoretical average time to process each frame on the host and then the device without overlap (host time + device time), to see the gain from host/device and kernel/memory overlap.
Calculate the average wasted time on the host (streamed device time - host time) time where the host could be performing useful operations without increasing the average processing time).
Timing without the profiler
Expand to inspect the source code
proc_frame_cuda7 = ProcFrameCuda6(rows_small,cols_small,rows_big,cols_big,2,check_res,SyncType.soft,True)ProcVid2(proc_frame_cuda7,lr)print(f'Mean times calculated over {n_frames} frames:')print(f'Time to process each frame on the device: {proc_frame_cuda7.FrameTimeMs():.2f} ms/frame')print(f'Time to process each frame (host/device): {gpu_time_6:.2f} ms/frame')print(f'-> Gain from memcpy/kernel overlap if device is saturated: {proc_frame_cuda7.FrameTimeMs()-gpu_time_6:.2f} ms/frame')hostTime, n_frames = ProcVid2(proc_frame_cuda6, lr, True)print(f'Time to read and decode each frame on the host: {hostTime:.2f} ms/frame')print(f'-> Total processing time host + device: {proc_frame_cuda7.FrameTimeMs()+hostTime:.2f} ms/frame')print(f'-> Gain from host/device overlap: {proc_frame_cuda7.FrameTimeMs()+hostTime - gpu_time_6:.2f} ms/frame')print(f'-> Currently waisted time on host: {gpu_time_6-hostTime:.2f} ms/frame')
Mean times calculated over 100 frames:
Time to process each frame on the device: 1.00 ms/frame
Time to process each frame (host/device): 0.97 ms/frame
-> Gain from memcpy/kernel overlap if device is saturated: 0.04 ms/frame
Time to read and decode each frame on the host: 0.71 ms/frame
-> Total processing time host + device: 1.71 ms/frame
-> Gain from host/device overlap: 0.74 ms/frame
-> Currently waisted time on host: 0.26 ms/frame
Analysis
Observations
It appears that we gained 0.04 ms/frame from the kernel/memory processing overlap on the device. Unfortunately we cannot say this for sure because the times compared here are from two separate runs due to the device timer overhead. That said, the implication is that our interpretation of the kernel/memory overlap seen in the Nvidia Visual Profiler is correct.
The total processing which needs to be performed on the host and device takes and average of 1.71 ms/frame which is 0.74 ms/frame greater than our final implementation, demonstrating the importance of using asynchronous device calls and CUDA streams.
We have 0.26 ms/frame to spare on the host which we can make use of without affecting the average frame time of 0.97 ms/frame.
Results and suggested optimization strategies
When calling OpenCV CUDA functions the most effective optimizations (in order of effectiveness/ease to implement) for this toy problem are given below. Whilst (1) will always be effective, the other optimizations will heavily depend on the CPU/GPU specifications, data size and the amount of processing which can be performed on the device before returning to the host. Therefore it is always beneficial to use a tool such as the Nvidia visual profiler to analyze your pipeline as you make changes.
Pre-allocate and pass all Numpy and/or GpuMat arrays (making sure they are the correct size) as function arguments to avoid them being allocated each time the function is called.
Try to design a processing pipeline which allows memory copies to overlap kernel calls and work to be performed on both the host and the device at the same time.
Use CUDA streams with pinned host memory and if you are working on windows consider calling stream.queryIfComplete() to force the WDDM driver to dispatch the CUDA calls.